This Algorithm Can Tell Which Number a Human Will Find Interesting
- यह अल्गोरिथम बता सकता है कि कौन सी संख्या एक मानव को दिलचस्प बनाती है (This Algorithm Can Tell Which Number a Human Will Find Interesting) के द्वारा यह बताया गया है कि गणित में अनुपम सौंदर्य है यदि उसे अनुभव किया जाए.जैसे यूलर ने जो अल्गोरिथम दिया उसका भी एसमें वर्णन किया गया है.
- आपको यह जानकारी रोचक व ज्ञानवर्धक लगे तो अपने मित्रों के साथ इस गणित के आर्टिकल को शेयर करें ।यदि आप इस वेबसाइट पर पहली बार आए हैं तो वेबसाइट को फॉलो करें और ईमेल सब्सक्रिप्शन को भी फॉलो करें जिससे नए आर्टिकल का नोटिफिकेशन आपको मिल सके।यदि आर्टिकल पसन्द आए तो अपने मित्रों के साथ शेयर और लाईक करें जिससे वे भी लाभ उठाए।आपकी कोई समस्या हो या कोई सुझाव देना चाहते हैं तो कमेंट करके बताएं।इस आर्टिकल को पूरा पढ़ें।
Also Read This Article:Differential equations basics

- परिणाम संकेत देता है कि मशीनों को एक दिन गणितीय लालित्य और सुंदरता को प्रशिक्षित करने के लिए प्रशिक्षित किया जा सकता है
गणित के उत्सुक गुणों में से एक इसकी सुंदरता है। लेकिन वास्तव में जो गणितज्ञ सुंदरता से मतलब रखते हैं, उसे पकड़ना मुश्किल है। - शायद सबसे प्रसिद्ध उदाहरण है यूलर का संबंध,e^{iπ} + 1=0, जो गणित के प्रतीत होते असंबंधित क्षेत्रों के बीच एक गहरी कड़ी को प्रकट करता है। उदाहरण के लिए, ometry ज्यामिति से आता है, ई और मैं बीजगणित से आते हैं, और आदिम 0 और 1 के साथ संचालन + और = संख्या सिद्धांत से आते हैं। वे इस तरह के एक सरल और अप्रत्याशित तरीके से संबंधित हैं जो गणितीय दुनिया के महान आश्चर्यों में से एक है।
Also Read This Article:Algorithm
2.और गणितीय सुंदरता के एक और घटक की ओर इशारा करता है:

- गणितीय पैटर्न किसी न किसी तरह से दिलचस्प होना चाहिए। इन दिलचस्प पैटर्न को पहचानना हमेशा एक विशिष्ट मानवीय क्षमता रही है।
- लेकिन हाल के वर्षों में, मशीनें बेहद सक्षम पैटर्न-पहचान उपकरण बन गई हैं। वास्तव में, उन्होंने मानव को चेहरे की पहचान, वस्तु की पहचान, और विभिन्न प्रकार की गेम-प्लेइंग भूमिकाओं के रूप में समझना शुरू कर दिया है।
- और इससे एक दिलचस्प संभावना पैदा होती है: क्या मशीन-सीखने वाले एल्गोरिदम गणित में दिलचस्प या सुरुचिपूर्ण पैटर्न की पहचान कर सकते हैं? क्या वे गणितीय सौंदर्य के मध्यस्थ भी हो सकते हैं?
- आज हमें न्यूयॉर्क राज्य में आईबीएम के टीजे वाटसन रिसर्च सेंटर में चाय वाह वू के काम के लिए धन्यवाद का जवाब मिलता है। वू ने एक ऐसी मशीन-शिक्षण एल्गोरिथ्म का निर्माण किया है, जिसने गणितीय संरचनाओं में कुछ प्रकार के लालित्य की पहचान करना सीखा है और इसका उपयोग यादृच्छिक लोगों से दिलचस्प दृश्यों को फ़िल्टर करने के लिए किया है।
- तकनीक एक असामान्य डेटाबेस का उपयोग करती है जिसे ऑनलाइन एनसाइक्लोपीडिया ऑफ इंटेगर सीक्वेंस कहा जाता है, जिसे मूल रूप से गणितज्ञ नील स्लोन द्वारा 1960 के दशक में बनाया गया था और 1996 में वेब पर रखा गया था।
- पूर्णांक अनुक्रम संख्याओं की एक श्रृंखला है जो एक नियम के अनुसार आदेशित होती है। प्रसिद्ध उदाहरणों में प्रमुख संख्याएँ शामिल हैं – वे संख्याएँ जिन्हें केवल स्वयं और 1 (A000040) से विभाजित किया जा सकता है; फाइबोनैचि अनुक्रम, जिसमें प्रत्येक पद पिछले दो पदों (A000045) का योग है; और यहां तक कि तुच्छ उदाहरण जैसे कि विषम संख्याओं या अनुक्रमों का क्रम जो 7 से शुरू होता है।
- वास्तव में, गणितज्ञ जो ओईएस चलाते हैं, “दिलचस्प” दृश्यों की तलाश में व्यापक रूप से जाल डालते हैं और इसलिए विशुद्ध रूप से सांस्कृतिक महत्व के साथ उदाहरणों की एक विस्तृत श्रृंखला शामिल करते हैं। इनमें प्राइम नंबर शामिल हैं जिनमें अनुक्रम 666 शामिल है, जानवर की तथाकथित संख्या।
डेटाबेस में 667 (A138563) संख्या वाले अभाज्य संख्याओं का क्रम भी शामिल है। यह संख्या महत्वपूर्ण मानी जाती थी क्योंकि जब फैक्स मशीनें आम थीं, तो लोगों के पास अक्सर एक फैक्स नंबर होता था जो कि उनका टेलीफोन नंबर प्लस होता था। दूसरे शब्दों में, यदि उनका टेलीफोन नंबर 123-4567 था, तो उनका फैक्स नंबर 123-4568 होगा। इस तरह से सोचने पर, 667 जानवर का फैक्स नंबर है, और इसलिए सांस्कृतिक महत्व (संपादक मानव हैं, सब के बाद)। - आज, इंटेगर सीक्वेंस डेटाबेस में कुछ 300,000 सीक्वेंस शामिल हैं, और हर दिन शौकीनों और पेशेवरों द्वारा समान रूप से प्रस्तुत किए जाते हैं, उनमें से कई गणित में नई और दिलचस्प समस्याओं पर इशारा करते हैं।
- वू ने जो कार्य किया था, वह इन “दिलचस्प” दृश्यों को यादृच्छिक रूप से उत्पन्न लोगों से अलग करने का एक तरीका खोजना था। और उनका विचार अनुभवजन्य कानूनों को खोजने का था जो “रोचकता” के उपायों के रूप में कार्य कर सकते हैं जो उन्हें निर्बाध लोगों से अलग कर सकते हैं।
- “अनुभवजन्य कानून प्रति से गणितीय प्रमेय नहीं हैं, लेकिन रिश्तों की अनुभवजन्य टिप्पणियां हैं जो कई प्राकृतिक और मानव निर्मित डेटा सेटों पर लागू होती हैं,” वू कहते हैं। उदाहरणों में इलेक्ट्रिकल इंजीनियरिंग में मूर का कानून और अर्थशास्त्र में 80/20 परेतो सिद्धांत शामिल हैं। बस ये “कानून” क्यों पूरी तरह से समझ में नहीं आते हैं, लेकिन फिर भी वे गैर-धारण करते हैं।
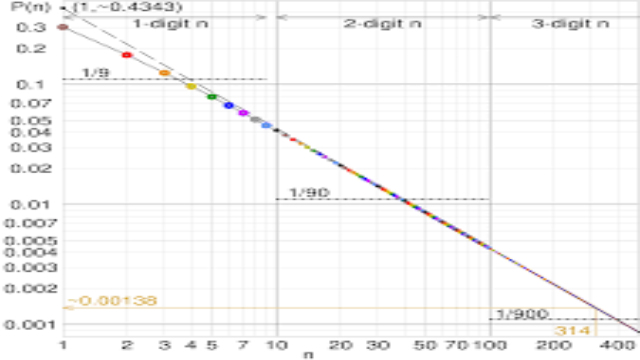
- एक अनुभवजन्य सिद्धांत जो कई डेटा सेटों पर लागू होता है, वह बेनफोर्ड का नियम है। यह 1881 में कनाडाई गणितज्ञ और खगोलविद साइमन न्यूकॉम्ब द्वारा खोजा गया था। न्यूकॉम्ब ने नोट किया कि लॉगरिदम टेबल की पुस्तकों में पहले के पृष्ठ बाद के पृष्ठों की तुलना में अधिक भारी थे, यह सुझाव देते हुए कि अंक 1 से शुरू होने वाले लॉगरिदम अधिक सामान्य थे।
- इससे उन्हें यह सिद्धांत तैयार करना पड़ा कि डेटा के किसी भी सेट में, किसी भी अन्य संख्या की तुलना में अधिक संख्या 1 से शुरू होगी। इसी विचार को 1930 के दशक में फ्रैंक बेनफोर्ड ने फिर से खोजा और लोकप्रिय बनाया।
- बेनफोर्ड का नियम कई प्रकार के डेटा सेटों पर लागू होता है, जैसे बिजली के बिल, सड़क के पते, शेयर की कीमतें, और इसी तरह। यह इतना अनुमानित है कि इसका इस्तेमाल वित्तीय खातों में धोखाधड़ी करने के लिए किया जा सकता है। लेकिन यह यादृच्छिक अनुक्रमों पर लागू नहीं होता है। वास्तव में क्यों स्पष्ट रूप से समझ में नहीं आता है।
- वास्तव में, यह एक पहेली है जो गणितज्ञों ने पाया है कि बेनफोर्ड का नियम कुछ पूर्णांक अनुक्रमों पर लागू होता है। लेकिन इन दृश्यों में यह कितना व्यापक रूप से लागू होता है?
- यह पता लगाने के लिए, वू ने मापा कि ओआईएस डेटाबेस से बेतरतीब ढंग से चुने गए 40,000 अनुक्रमों में पहले अंकों के वितरण को कानून कितनी अच्छी तरह से बताता है।
- यह पता चलता है कि बेनफोर्ड की विधि फसलों की अपेक्षा अधिक बार होती है। वू कहते हैं, “परिणाम बताते हैं कि कई, लेकिन सभी नहीं, अनुक्रम कुछ हद तक बेनफोर्ड के कानून से संतुष्ट हैं, जिन्होंने पाया कि टेलर लॉ नामक एक अन्य अनुभवजन्य सिद्धांत भी व्यापक रूप से मौजूद था।
अगला सवाल एक सरल कदम था: क्या बेनफोर्ड के कानून और टेलर के कानून का उपयोग OEIS में यादृच्छिक क्रमों को अलग करने के लिए किया जा सकता है? - यह पता लगाने के लिए, वू ने यादृच्छिक पूर्णांक के 40,000 अनुक्रम उत्पन्न किए और इन्हें OEIS से चुने गए 40,000 अनुक्रमों में जोड़ा। फिर उन्होंने बेनफोर्ड के नियम और टेलर के नियम का उपयोग करके OEIS अनुक्रमों को देखने और उन्हें यादृच्छिक दृश्यों से अलग करने के लिए मशीन-लर्निंग एल्गोरिदम को प्रशिक्षित किया।
- परिणाम प्रभावशाली हैं। एल्गोरिथ्म ने 0.999 की सटीकता और 0.9984 की सटीकता के साथ काम किया। यह महत्वपूर्ण है क्योंकि यह “दिलचस्प” दृश्यों को स्पॉट करने के लिए एक स्वचालित प्रक्रिया की संभावना स्थापित करता है।
- एक आवेदन तुरंत स्पष्ट है। ओईआईएस चलाने वाले गणितज्ञों को वर्तमान में एक वर्ष में लगभग 10,000 प्रस्तुतियाँ करनी होती हैं। तो सबसे दिलचस्प स्वचालित रूप से स्पॉट करने का एक तरीका उपयोगी हो सकता है।
- हालाँकि, दृष्टिकोण की कुछ महत्वपूर्ण सीमाएँ हैं। गणितज्ञों ने कई दिलचस्प और महत्वपूर्ण अनुक्रमों को परिभाषित किया है जिनकी अनंत संख्या है, लेकिन गणना करना कठिन है। नतीजतन, डेटाबेस में केवल कुछ ही शब्द होते हैं। इस तरह के मशीन-आधारित विश्लेषण के लिए ये स्पष्ट रूप से उपयुक्त नहीं हैं।
- व्यापक प्रश्न यह है कि क्या यह दृष्टिकोण गणित में लालित्य या सुंदरता की पहचान कर सकता है। जैसा कि वू पूछता है: “क्या मशीन सीखना वैज्ञानिक ज्ञान के गुणात्मक गुणों की पहचान कर सकता है; यानी, क्या हम बता सकते हैं कि क्या वैज्ञानिक परिणाम सुरुचिपूर्ण, सरल या दिलचस्प है? “
यह लक्ष्य पूरी तरह से व्यर्थ नहीं हो सकता है। यदि बेनफोर्ड और टेलर जैसे अनुभवजन्य कानून “रोचकता” के सूचक हैं, जैसा कि यह काम बताता है, तो शायद इस एल्गोरिथ्म को कम से कम कुछ स्तर पर, शान का एक मध्यस्थ माना जा सकता है। - यूलर, महाकाव्य के संबंध और इतिहास के सबसे महान गणितज्ञों में से एक, निश्चित रूप से मोहित होगा।
Also Read This Article:How fedex employee discovered the world prime number
- उपर्युक्त आर्टिकल में यह अल्गोरिथम बता सकता है कि कौन सी संख्या एक मानव को दिलचस्प बनाती है (This Algorithm Can Tell Which Number a Human Will Find Interesting) के बारे में बताया गया है.
This Algorithm Can Tell Which Number a Human Will Find Interesting
This Algorithm Can Tell Which Number a Human Will Find Interesting

यह अल्गोरिथम बता सकता है कि कौन सी संख्या एक मानव को दिलचस्प बनाती है
(This Algorithm Can Tell Which Number a Human Will Find Interesting)
के द्वारा यह बताया गया है कि गणित में अनुपम सौंदर्य है यदि उसे अनुभव
किया जाए.जैसे यूलर ने जो अल्गोरिथम दिया उसका भी एसमें वर्णन किया गया है.
| No. | Social Media | Url |
|---|---|---|
| 1. | click here | |
| 2. | you tube | click here |
| 3. | click here | |
| 4. | click here | |
| 5. | Facebook Page | click here |
| 6. | click here |





About Author
Satyam
Lekhak Ke Baare Mein (About the Author) **Satyam Narain Kumawat** **Website Name:Satyam Mathematics** *Owner:satyamcoachingcentre.in* *Sthan:Manoharpur,Jaipur (Rajasthan)* **Teaching Mathematics aur Anya Anubhav** ***Shiksha:**B.sc.,B.Ed.,(M.sc. star Ke Mathematics Ko Padhane ka Anubhav),B.com.,M.com. Ke vishayon Ko Padhane ka Anubhav,Philosophy,Psychology,Religious,sanskriti Mein Gahri Ruchi aur Adhyayan ***Anubhav:**phichale 23 varshon se M.sc.,M.com.,Angreji aur Vigyan Vishayon Mein Shikshaka Ka Lamba Anubhav ***Visheshagyata:*Maths,Adhyatma (spiritual),Yog vishayon ka vistrit Gyan* ****In Brief:I have read about M.sc. books,psychology,philosophy,spiritual, vedic,religious,yoga,health and different many knowledgeable books.I have about 23 years teaching experience upto M.sc. ,M.com.,English and science. Updated on 18.06.2026

{kind=link}